
Security
Okay, this may not be a topic you were expecting, but I recently attended a meeting of JHU EP staff and we were talking about "foundation" topics that should be included in any CS/IS major. I currently work in computer security, so I'm more aware of security issues than some, and one thing that seems to be always "tacked on" to a software product is security.
And I'll admit, most of the time when you are given a problem to solve, you think about how to solve it. You may consider alternate algorithms for performance or memory issue, you may worry about User Interface issues or even maintainability, but rarely is security "baked in" to an application from the beginning. And right there is the number one problem with security....it needs to be considered every step of the way.
So, this week we are going to step away from new tools and techniques, and talk a bit about security. It turns out security comes in all sorts of flavors, some you may be able to control, some you can't...but you should be aware of anyway. Look, the bottom line is that when you create a web application, you are already giving other people paths into your system. It is up to you to make sure they can't get to places you don't want them to get to, or to do things you didn't intend to let them do.
You might be surprised how many companies operate without any good software security policy. It's something that everybody is aware of, but often nobody wants to take the time to spell it out. It's just "assumed" that a software developer knows about security.
So, let's start out with the basics and work from there...Yes, I'm going to hit a lot of topics on this one, but I think it is important that you are aware of everything that can be done to make your application secure. No, this isn't a cyber-security class, so I'm going to describe some issues, but not go into full depth on them if it is outside of your typical control.
Also, as a software developer, you might not think you need to know about all of these topics...I beg to differ. You may not need to know the ins and outs of every topic, but it is good to be aware of the *environment* you work in, even if you aren't personally responsible for every aspect of the system your software is running on.
Operating System
While I'm not going to get in to the religious wars of which Operating System is best, I'll at least go on record as saying that most of the Windows, Linux or other *nix based servers are very stable platforms, you need to make sure that patches are applied.

You might think that goes without saying, but Linux systems are famous for not applying patches because it may "break things". There are a lot of Linux servers that don't get updated as often as they should.
Why don't systems get updated, well, one common answer is people are lazy...but I don't think that's fair. One of the things I do is act as a system administrator...for the very computer that is hosting this web page! And...I...hate...doing...patches. It's just another form of Russian Roulette. Patches or upgrades to an OS should be a piece of cake, they've been tested right? Oh no, for those of you that have had to do this task, you soon realize never assume things will go well. Every time you patch, you take the risk of bricking your system, and then what? Can you really afford the downtime? When I patch, I work from test systems, to devel systems and finally the production systems...it doesn't help...somehow, the most critical system has issues. Sometimes it isn't even directly patch related. One time when I did patches the reboot on a machine caused (or made apparent) a hard drive failure.
So, patches aren't always done...because admins are often afraid of killing their systems, and they play the risk game. While you probably won't ever have to work at this level, it is still something to be aware of.
System "Hardening"
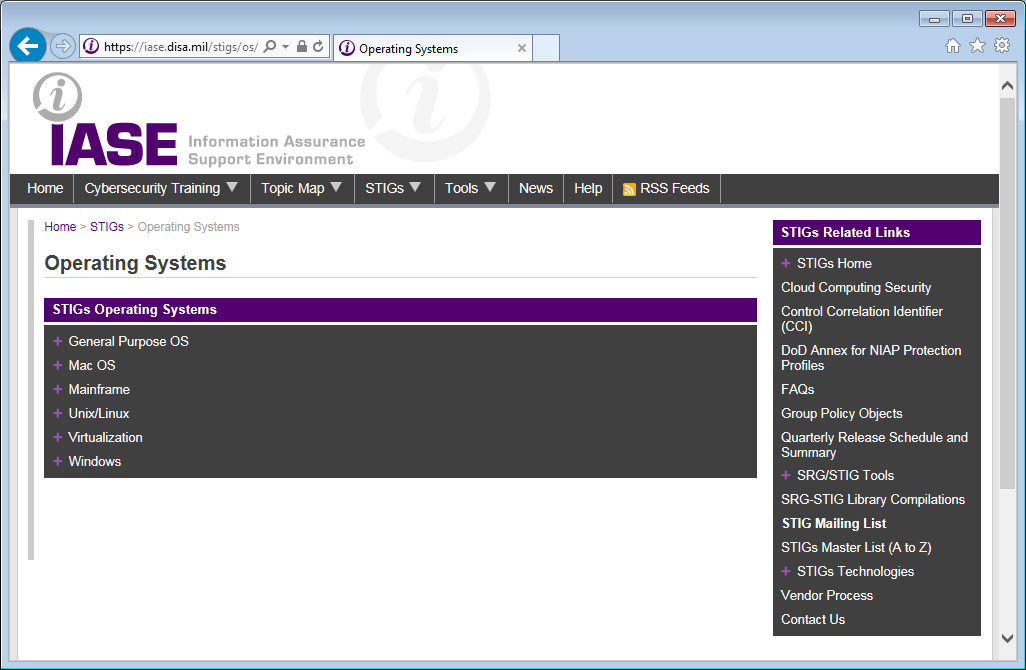
Patches aren't the only thing you can do to make an Operating System more secure. You can also do a hardening (lockdown) of an Operating System to make sure that security settings are as tight as possible to minimize vulnerabilities. The gold standard for securing a system is the Defense Information System Agency (DISA) Security Technical Information Guide (STIG) for many of the popular Operating Systems.
Least Privilege
Accounts on a system are another often overlooked feature of security. Least Privilege basically means that a person or process gets just enough authority (permissions) to accomplish its task. Often times, this means a lot more work to properly set up a web server, because the more permissions you have, the "easier" it is to get things to work. The nice thing is that most modern operating systems that have web server "pre-installed" or that are installed using a package system will create accounts and permissions that follow this guidance. However...many an admin won't use Apache or Tomcat that comes shipped with RedHat, they want to compile and install their own version! Which leads to them installing the software without using a packaging system, which may tempt them to install it as root because:
- It makes accessing files easier
- It makes access to "privileged ports" (80 &443) easier
- They just have bad habits
So, why do we worry about what privileges the web server has? Simple, if somebody finds a vulnerability in your web server that allows them to get a "shell" or execute commands on your system, if the system is running as root (administrator), then they can now get to anything on the system. If instead, your Apache web server is running as something like the webservd user (a common "username" for web server usage), then if an attacker does compromise your web server, they still need to figure out how to elevate privileges on the system before they can get to anything they want.
Firewalls
 I'm mentioning them, only because they are a commonly thought of control.
I'm mentioning them, only because they are a commonly thought of control.
Local Firewalls. A "Local" firewall is typically configured on the machine itself. Consider it a last line of firewall defense, as often systems are behind a corporate or network (site)firewall blocking access to an entire network. Most Operating Systems already use pre-configured "local" firewalls to block port access. Given that, ports 80 (http) and 443 (https) are almost always open. Now if you have some type of SQL server that needs to communicate, that may cause you to open up another firewall port, if so, you need to make sure that the site firewall is configured to not allow access to your SQL ports.
Site Firewalls. A site firewall sits between your network and the rest of the Internet. This is hopefully what protects your server from people tying to "poke" at it to see if they can get in. Odds are, you are (or will not) be responsible for this configuration, but the bottom line is that a good firewall only lets in the connections you want. This may be only on port 80/443 and nothing else. Most firewalls are state aware, so if you initiate a connection outside of the firewall, it will allow return communications, but won't let an outside entity initiate a connection.
Anti-virus
Actually, this can come in play for a web server, if the server supports some type of file upload ability. If you allow your users to upload a document, you want to use your anti-virus to scan any documents uploaded for any virus/malware issues. Be aware that most anti-virus programs, even while they say they will run on non-windows platforms, basically check for Windows virus/malware. This is because they assume your system is an email server and you are scanning email attachments. People may try to argue on this one, but the bottom line is that Linux is still basically virus free. If you read up on things, the few things ever found for Linux were basically proof of concept and not seen "in the wild".
Either way, it is still good procedure to scan any uploaded files.
Encryption of Data at Rest
Oh boy, this was a requested "item" to be covered in this module. I'll give you two takes on this requirement.
The first is the most commonly accepted definition of "Encryption of Data at Rest (EDR)". Basically, most government sponsors want data to be on encrypted drives. Now I know that to the detail oriented, this is not fulfilling the true meaning of EDR, but 95% of all government sponsors consider this to be the proper implementation of Data at Rest for government "authorized" systems. The idea here is that if the drives are "lost" or improperly disposed of, data on those drives won't be available to a third party. My personal opinion is that implementing this requirement this particular way is "do-able" and hence the govenment is accepting this solution.
However, if you want to be a stickler, Data at Rest is any data currently not being used in a process or calculation. This means any files, databases, etc on your system should be encrypted unless they are loaded into memory to be used. This is a *very* difficult, and computational intensive process, and believe it or not, I do not know of any systems using this definition, even though in 2019 I am beginning to see this "version" of the definition being used in literature. This is commonly called "Transparent Data Encryption (TDE)" and is supported by Oracle and Microsoft SQL. I am not aware of any open source solution to this requirement at present. Supposedly the Commercial version of MySQL does support TDE, but not the free version.
Web Server
Okay, this can be a rather long topic, and I'm not going to go through step-by-step how to lock down every web server out there. If you are interested, you can go to the DISA website, where they have a very nice table of STIGs for many of the popular web servers. These will go, into very great detail, how to secure each web server.
The URL for the web server STIGs is https://iase.disa.mil/stigs/app-security/web-servers/Pages/index.aspx
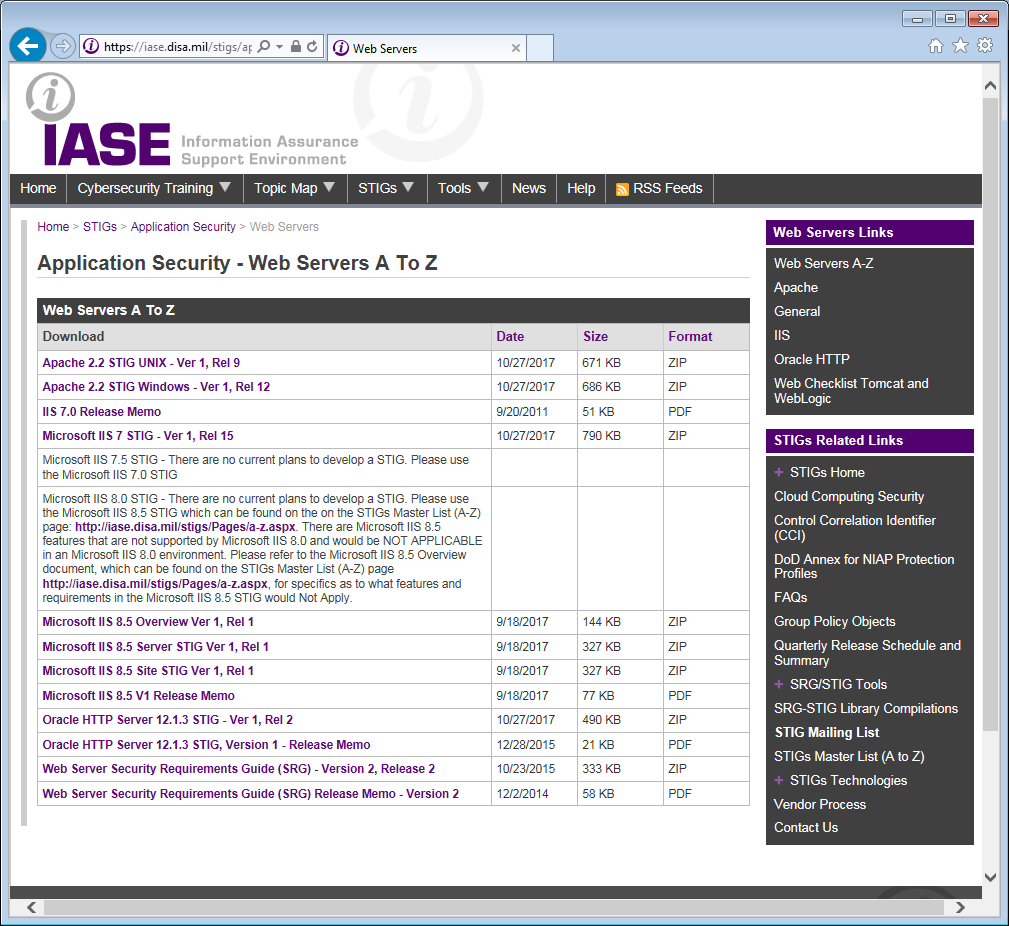
One particular lesson though about setting up a Web Server configuration on Unix/Linux, is the option to "Follow Soft Links". I'm sure it is mentioned in the STIGs, but it is worth mentioning here that if this is enabled on Unix/Linux, it can often open up your entire file system to a browser client if the soft links are used incorrectly.
MySQL
Okay, I saw this comic years ago, but I never forgot it...basically covers the joys of MySQL injection in four wonderful panels.

Exploits of a Mom from https://xkcd.com
So, what is SQL injection? It is basically providing more than a text field asks for, and then just passing that text field off to a query without doing any checking. In the example above, a second SQL statement "DROP TABLE students", was inserted after the students name. So if you had a SQL statement that looked something like this
SELECT id FROM students WHERE firstname='<data in first name field>' and lastname = '<data in last name field>'
So, using the name above you would get this
SELECT id FROM students WHERE firstname='Robert';DROP TABLE Students;-- ' and lastname = 'Evans';
Now, the -- acts as a start of a comment, so what you actually execute are TWO statements
- SELECT id FROM students WHERE firstname='Robert';
- DROP TABLE Students;
Which in turn deletes all of the student records.
So, how do you defend against this interesting ability to "add" code to a SQL query, well, in Java there is something called a PreparedStatement. The idea is that a PreparedStatement is precompiled, and then anything you enter into the variable field is sanitized by the class. So if we had used a PreparedStatement above, the extra DROP code would not have been executed. Remember, for a PreparedStatement to actually do it's job, you need to use the "?" parameter in the initial query definition for a variable and then use the setString() method to set the value.
Now, if you don't append user input, or just insert a calculated number, you could get away with a standard SQL query, but, best practices are to use a PreparedStatement to sanitize and check your inputs.
Web applications
One of the biggest things to keep in mind when writing a web application is that the client you design will be used by your "good" users, but nefarious users can basically craft anything they want with a tool and send it right to your server. Input validation on the client side is good because it is fast, immediate, and minimizes "good user" error, but since somebody can craft their own URL to send to your server, your server can never assume that the input it gets has been scrubbed by your well-written client.
You have to assume that every bit of input to your server is suspect, and needs to go through verification before use. The trust we have in data that comes from a browser, even if we validate the input on the client AND use SSL for security should basically be zero. It is very easy for a user to modify markup before sending, or they could even use a CLI utility like curl to submit their own URL and data. In order to ensure the integrity of incoming data, validation needs to be handled on the server.
OWASP top 10

So, before I go in to some of my own topics, let's hit the top 10 web application security risks for 2017 as published by the Open Web Application Security Project (OWASP). The last update to this list was 2013, so this is still fairly up to date. The following is taken directly from https://www.owasp.org/images/7/72/OWASP_Top_10-2017_%28en%29.pdf.pdf. I have included some of the definitions provided in this document, but the document contains much more that what is used below, I suggest you take a look at it as well.
A1: Injection.
Injection flaws, such as SQL, NoSQL, OS, and LDAP injection, occur when untrusted data is sent to an interpreter as part of a command or query. The attacker’s hostile data can trick the interpreter into executing unintended commands or accessing data without proper authorization.
Is the Application Vulnerable? An application is vulnerable to attack when:
- User-supplied data is not validated, filtered, or sanitized by the application.
- Dynamic queries or non-parameterized calls without context-aware escaping are used directly in the interpreter.
- Hostile data is used within object-relational mapping (ORM) search parameters to extract additional, sensitive records.
- Hostile data is directly used or concatenated, such that the SQL or command contains both structure and hostile data in dynamic queries, commands, or stored procedures.
Some of the more common injections are SQL, NoSQL, OS command, Object Relational Mapping (ORM), LDAP, and Expression Language (EL) or Object Graph Navigation Library (OGNL) injection. The concept is identical among all interpreters. Source code review is the best method of detecting if applications are vulnerable to injections, closely followed by thorough automated testing of all parameters, headers, URL, cookies, JSON, SOAP, and XML data inputs. Organizations can include static source (SAST) and dynamic application test (DAST) tools into the CI/CD pipeline to identify newly introduced injection flaws prior to production deployment.
A2: Broken Authentication
Application functions related to authentication and session management are often implemented incorrectly, allowing attackers to compromise passwords, keys, or session tokens, or to exploit other implementation flaws to assume other users’ identities temporarily or permanently.
Is the Application Vulnerable? Confirmation of the user's identity, authentication, and session management are critical to protect against authentication-related attacks.There may be authentication weaknesses if the application:
- Permits automated attacks such as credential stuffing, where the attacker has a list of valid usernames and passwords.
- Permits brute force or other automated attacks.
- Permits default, weak, or well-known passwords, such as "Password1" or "admin/admin“.
- Uses weak or ineffective credential recovery and forgot-password processes, such as "knowledge-based answers", which cannot be made safe.
- Uses plain text, encrypted, or weakly hashed passwords (see A3:2017-Sensitive Data Exposure).
- Has missing or ineffective multi-factor authentication.
- Exposes Session IDs in the URL (e.g., URL rewriting).
- Does not rotate Session IDs after successful login.
- Does not properly invalidate Session IDs. User sessions or authentication tokens (particularly single sign-on (SSO) tokens) aren’t properly invalidated during logout or a period of inactivity.
A3: Sensitive Data Exposure
Many web applications and APIs do not properly protect sensitive data, such as financial, healthcare, and PII. Attackers may steal or modify such weakly protected data to conduct credit card fraud, identity theft, or other crimes. Sensitive data may be compromised without extra protection, such as encryption at rest or in transit, and requires special precautions when exchanged with the browser.
Is the Application Vulnerable? The first thing is to determine the protection needs of data in transit and at rest. For example, passwords, credit card numbers, health records, personal information and business secrets require extra protection, particularly if that data falls under privacy laws, e.g. EU's General Data Protection Regulation (GDPR), or regulations, e.g. financial data protection such as PCI Data Security Standard (PCI DSS). For all such data:
- Is any data transmitted in clear text? This concerns protocols such as HTTP, SMTP, and FTP. External internet traffic is especially dangerous. Verify all internal traffic e.g. between load balancers, web servers, or back-end systems.
- Is sensitive data stored in clear text, including backups?
- Are any old or weak cryptographic algorithms used either by default or in older code?
- Are default crypto keys in use, weak crypto keys generated or re-used, or is proper key management or rotation missing?
- Is encryption not enforced, e.g. are any user agent (browser) security directives or headers missing?
- Does the user agent (e.g. app, mail client) not verify if the received server certificate is valid?
A4: XML External Entities (XXE)
Many older or poorly configured XML processors evaluate external entity references within XML documents. External entities can be used to disclose internal files using the file URI handler, internal file shares, internal port scanning, remote code execution, and denial of service attacks.
Is the Application Vulnerable? Applications and in particular XML-based web services or downstream integrations might be vulnerable to attack if:
- The application accepts XML directly or XML uploads, especially from untrusted sources, or inserts untrusted data into XML documents, which is then parsed by an XML processor.
- Any of the XML processors in the application or SOAP based web services has document type definitions (DTDs)enabled. As the exact mechanism for disabling DTD processing varies by processor, it is good practice to consult a reference such as the OWASP Cheat Sheet 'XXE Prevention’.
- If your application uses SAML for identity processing within federated security or single sign on (SSO) purposes. SAML uses XML for identity assertions, and may be vulnerable.
- If the application uses SOAP prior to version 1.2, it is likely susceptible to XXE attacks if XML entities are being passed to the SOAP framework.
- Being vulnerable to XXE attacks likely means that the application is vulnerable to denial of service attacks including the Billion Laughs attack
A5: Broken Access Control
Restrictions on what authenticated users are allowed to do are often not properly enforced. Attackers can exploit these flaws to access unauthorized functionality and/or data, such as access other users' accounts, view sensitive files, modify other users’ data, change access rights, etc.
Is the Application Vulnerable? Access control enforces policy such that users cannot act outside of their intended permissions. Failures typically lead to unauthorized information disclosure, modification or destruction of all data, or performing a business function outside of the limits of the user. Common access control vulnerabilities include:
- Bypassing access control checks by modifying the URL, internal application state, or the HTML page, or simply using a custom API attack tool.
- Allowing the primary key to be changed to another users record, permitting viewing or editing someone else's account.
- Elevation of privilege. Acting as a user without being logged in, or acting as an admin when logged in as a user.
- Metadata manipulation, such as replaying or tampering with a JSON Web Token (JWT)access control token or a cookie or hidden field manipulated to elevate privileges, or abusing JWT invalidation
- CORS misconfiguration allows unauthorized API access.
- Force browsing to authenticated pages as an unauthenticated user or to privileged pages as a standard user. Accessing API with missing access controls for POST, PUT and DELETE.
A6: Security Misconfiguration
Security misconfiguration is the most commonly seen issue. This is commonly a result of insecure default configurations, incomplete or ad hoc configurations, open cloud storage, misconfigured HTTP headers, and verbose error messages containing sensitive information. Not only must all operating systems, frameworks, libraries, and applications be securely configured, but they must be patched and upgraded in a timely fashion.
Is the Application Vulnerable? The application might be vulnerable if the application is:
- Missing appropriate security hardening across any part of the application stack, or improperly configured permissions on cloud services.
- Unnecessary features are enabled or installed (e.g. unnecessary ports, services, pages, accounts, or privileges).
- Default accounts and their passwords still enabled and unchanged.
- Error handling reveals stack traces or other overly informative error messages to users.
- For upgraded systems, latest security features are disabled or not configured securely.
- The security settings in the application servers, application frameworks (e.g. Struts, Spring, ASP.NET), libraries, databases, etc. not set to secure values.
- The server does not send security headers or directives or they are not set to secure values.
- The software is out of date or vulnerable
A7: Cross-Site Scripting (XSS)
XSS flaws occur whenever an application includes untrusted data in a new web page without proper validation or escaping, or updates an existing web page with user-supplied data using a browser API that can create HTML or JavaScript. XSS allows attackers to execute scripts in the victim’s browser which can hijack user sessions, deface web sites, or redirect the user to malicious sites
XSS occurs when a web application takes data from users and includes it into a dynamic web page. For example, if you are allowed to post comments to a page, if the page isn't careful, it can allow a maliscious user to include JavaScript in their post (or a link), that will get embedded in the page content that is produced.
There are three forms of XSS, usually targeting users' browsers:
Reflected XSS:The application or API includes unvalidated and unescaped user input as part of HTML output. A successful attack can allow the attacker to execute arbitrary HTML and JavaScript in the victim’s browser. Typically the user will need to interact with some malicious link that points to an attacker-controlled page, such as malicious watering hole websites, advertisements, or similar.
Stored XSS:The application or API stores unsanitized user input that is viewed at a later time by another user or an administrator. Stored XSS is often considered a high or critical risk.
DOM XSS:JavaScript frameworks, single-page applications, and APIs that dynamically include attacker-controllable data to a page are vulnerable to DOM XSS. Ideally, the application would not send attacker-controllable data to unsafe JavaScript APIs.
Typical XSS attacks include session stealing, account takeover, MFA bypass, DOM node replacement or defacement (such as trojan login panels), attacks against the user's browser such as malicious software downloads, key logging, and other client-side attacks.
A8: Insecure Deserialization
Insecure deserialization often leads to remote code execution. Even if deserialization flaws do not result in remote code execution, they can be used to perform attacks, including replay attacks, injection attacks, and privilege escalation attacks
This attack takes place when you transfer "Objects" vice primitive data (integers, strings, etc).
Is the Application Vulnerable? Applications and APIs will be vulnerable if they deserialize hostile or tampered objects supplied by an attacker. This can result in two primary types of attacks:
- Object and data structure related attacks where the attacker modifies application logic or achieves arbitrary remote code execution if there are classes available to the application that can change behavior during or after deserialization.
- Typical data tampering attacks, such as access-control-related attacks, where existing data structures are used but the content is changed.Serialization may be used in applications for:
- Remote-and inter-process communication (RPC/IPC)
- Wire protocols, web services, message brokers•Caching/Persistence•Databases, cache servers, file systems
- HTTP cookies, HTML form parameters, API authentication tokens
A9: Using Components with Known Vulnerabilities
Components, such as libraries, frameworks, and other software modules, run with the same privileges as the application. If a vulnerable component is exploited, such an attack can facilitate serious data loss or server takeover. Applications and APIs using components with known vulnerabilities may undermine application defenses and enable various attacks and impacts.
Is the Application Vulnerable? You are likely vulnerable:
- If you do not know the versions of all components you use (both client-side and server-side). This includes components you directly use as well as nested dependencies.
- If software is vulnerable, unsupported, or out of date. This includes the OS, web/application server, database management system (DBMS), applications, APIs and all components, runtime environments, and libraries.
- If you do not scan for vulnerabilities regularly and subscribe to security bulletins related to the components you use.
- If you do not fix or upgrade the underlying platform, frameworks, and dependencies in a risk-based, timely fashion. This commonly happens in environments when patching is a monthly or quarterly task under change control, which leaves organizations open to many days or months of unnecessary exposure to fixed vulnerabilities.
- If software developers do not test the compatibility of updated, upgraded, or patched libraries.
- If you do not secure the components' configurations
A10: Insufficient Logging & Monitoring
Insufficient logging and monitoring, coupled with missing or ineffective integration with incident response, allows attackers to further attack systems, maintain persistence, pivot to more systems, and tamper, extract, or destroy data. Most breach studies show time to detect a breach is over 200 days, typically detected by external parties rather than internal processes or monitoring
Is the Application Vulnerable? Insufficient logging, detection, monitoring and active response occurs any time:
- Auditable events, such as logins, failed logins, and high-value transactions are not logged.
- Warnings and errors generate no, inadequate, or unclear log messages.
- Logs of applications and APIs are not monitored for suspicious activity.
- Logs are only stored locally.•Appropriate alerting thresholds and response escalation processes are not in place or effective.
- Penetration testing and scans by DASTtools (such as OWASP ZAP) do not trigger alerts.
- The application is unable to detect, escalate, or alert for active attacks in real time or near real time.You are vulnerable to information leakage if you make logging and alerting events visible to a user or an attacker
Man in the Middle (MITM) Attacks
A MITM attack involves a third party who somehow manages to pretend to be the target website you are trying to get to. For example, lets say you sit down at a public WiFi spot and try to get to "Your Bank USA" website. A MITM attack works by somehow poisoning the DNS tables or intercepting your https request to your bank, and then relaying your information to the bank as you submit it. To you, it looks like you have reached your desired web page, but instead, it is being relayed from the attackers system, thus allowing them to read all of your input before sending it to the target site.
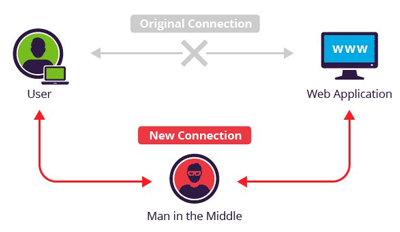
As a web designer, there isn't much you can do to prevent MITM attacks, as they don't really rely on website vulnerabilites (as long as you at least use https). This particular security attack tends to rely on users maintaining vigilant security and paying attention to links and https information.
Using https makes it very difficult for a hostile entity to impersonate a valid site, as they would somehow have to get hold of a valid cert for that domain, which is very unusual (although it has happened from time to time).
Input Validation
Input validation is the process of verifying that the data that you pull from an incoming URL is in the form you expect it to be. Since most everything that comes in, comes in as a String, you can do a lot of validation during the parsing process. Input validation can consist of:
- Ensuring numbers are within a given range, or greater than 0
- Ensure numbers are formatted properly
- Ensure strings are the correct length (always set a limit)
- Ensure strings have expected characters
- Ensure values are non-null when appropriate
The concept of only accepting input of known types is known as whitelisting. The idea is to only let things by your filter that adhere to the rules you have in place. The other way of doing things is called blacklisting, and the idea here is to identify the exact things you want to prevent. While tempting, this technique is far less powerful than whitelisting because when something new comes along, it gets by. The downside of whitelisting, is of course, that if you forget to enable something to get by, it doesn't...so you are forced to cover every case from day one with white listing
So, whitelisting is best, followed by blacklisting. Be as restrictive as you can with any accepted inputs, and check EVERYTHING.
Output Encoding
Just like MySQL Injection can introduce bad code into SQL, if you don't make sure your output is sanitized, an unscrupulous person might put a bad JavaSript command as part of their name, so that when you display the name in another page, the JavaScript will run as well. While this doesn't make your own site more secure, it avoid sending users off to bad places.
Storing Passwords
Okay, you may think this is obvious, but in 2019, Facebook was found to have stored MILLIONS of user passwords in plaintext on their systems....
The following is from an excellent article by Paul Ducklin at https://nakedsecurity.sophos.com/2013/11/20/serious-security-how-to-store-your-users-passwords-safely/
Basically if you need to store a user's password, how do you do it correctly...and by correctly I mean non-reversibility, no repeated hashes and no hint of password length.
I could re-write the text, but I'll copy and paste from the above article for your reading enjoyment. The following is directly from the above link with some formatting of numbers to avoid using images from the article.
Attempt One – On the grounds that you intend – and, indeed, you ought – to prevent your users’ passwords from being stolen in the first place, it’s tempting just to keep your user database in directly usable form, like this:
evansrb1:Robert Evans:Password1 mithcrj1:Robert Mitchell:ILoveLinux alpha:John Colter:FebruaryIV2018 radtke:Karen Radkte:montyPython durbin:Lani Durbin:montyPythonIf you are running a small network, with just a few users whom you known well, and whom you support in person, you might even consider it an advantage to store passwords unencrypted.
That way, if someone forgets their password, you can just look it up and tell them what it is.
Don’t do this, for the simple reason that anyone who gets to peek at the file immediately knows how to login as any user.
Worse still, they get a glimpse into the sort of password that each user seems to favor, which could help them guess their way into other accounts belonging to that user.
Evans, for example, went for the worst password ever; Radtke and Durbin used a Monty Python theme, and Colter used a date that probably has some personal significance.
The point is that neither you, nor any of your fellow system administrators, should be able to look up a user’s password.
It’s not about trust, it’s about definition: a password ought to be like a PIN, treated as a personal identification detail that is no-one else’s business.
Attempt Two – encrypt the passwords in the database
Encrypting the passwords sounds much better.
You could even arrange to have the decryption key for the database stored on another server, get your password verification server to retrieve it only when needed, and only ever keep it in memory.
That way, users’ passwords never need to be written to disk in unencrypted form; you can’t accidentally view them in the database; and if the password data should get stolen, it would just be shredded cabbage to the crooks.
This is the approach Adobe took, ending up with something similar to this:
evansrb1:Robert Evans:U2FsdGVkX19FFL9jAsi5nGK040ebXN5I mithcrj1:Robert Mitchell:U2FsdGVkX18pbgeYySGMZiRZXMdsHVBH15OgKlWHzeE= alpha:John Colter:U2FsdGVkX18pbgeYySAnvaLjiBHNLKVBH15OgKoIi87k8 radtke:Karen Radkte::U2FsdGVkX18pbgYLMNoIi87keYySAnvaLjiBHNLKVBH15OgKlWHze durbin:Lani Durbin:U2FsdGVkX18pbgYLMNoIi87keYySAnvaLjiBHNLKVBH15OgKlWHzeYou might consider this sort of symmetric encryption an advantage because you can automatically re-encrypt every password in the database if ever you decide to change the key (you may even have policies that require that), or to shift to a more secure algorithm to keep ahead of cracking tools.But don’t encrypt your password databases reversibly like this.
You haven’t solved the problem we mentioned in Attempt One, namely that neither you, nor any of your fellow system administrators, should be able to recover a user’s password.
Worse still, if crooks manage to steal your database and to acquire the password at the same time, for example by logging into your server remotely, then Attempt Two just turns into Attempt One.
By the way, the password data above has yet another problem, namely that we used DES in such a way that the same password produces the same data every time.
We can therefore tell automatically that Radtke and Durbin have the same password, even without the decryption key, which is a needless information leak – as is the fact that the length of the encrypted data gives us a clue about the length of the unencrypted password.
We will therefore insist on the following requirements:
- Users’ passwords should not be recoverable from the database.
- Identical, or even similar, passwords should have different hashes.
- The database should give no hints as to password lengths.
Attempt Three – hash the passwords
Requirement One above specifies that “users’ passwords should not be recoverable from the database.”
At first glance, this seems to demand some sort of “non-reversible” encryption, which sounds somewhere between impossible and pointless.
But it can be done with what’s known as a cryptographic hash, which takes an input of arbitrary length, and mixes up the input bits into a sort of digital soup.
As it runs, the algorithms strains off a fixed amount of random-looking output data, finishing up with a hash that acts as a digital fingerprint for its input.
Mathematically, a hash is a one-way function: you can work out the hash of any message, but you can’t go backwards from the final hash to the input data.
A cryptographic hash is carefully designed to resist even deliberate attempts to subvert it, by mixing, mincing, shredding and liquidizing its input so thoroughly that, at least in theory:
- You can’t create a file that comes out with a predefined hash by any method better than chance.
- You can’t find two files that “collide”, i.e. have the same hash (whatever it might be), by any method better than chance.
- You can’t work out anything about the structure of the input, including its length, from the hash alone.
Well-known and commonly-used hashing algorithms are MD5, SHA-1 and SHA-256 and SHA-512.
Of these, MD5 has been found not to have enough “mix-mince-shred-and-liquidise” in its algorithm, with the result that you can comparatively easily find two different files with the same hash.
This means it does not meet its original cryptographic promise – so do not use it in any new project.
SHA-1 is computationally quite similar to MD5, albeit more complex, and in early 2017, a collision – two files with the same hash – was found 100,000 times faster than you’d have expected.
So you should avoid SHA-1 as well.
We’ll use SHA-256, which gives us this if we apply it directly to our sample data (the hash has been truncated to make it fit neatly in the diagram):
The hashes are all the same length, so we aren’t leaking any data about the size of the password.
Also, because we can predict in advance how much password data we will need to store for each password, there is now no excuse for needlessly limiting the length of a user’s password. (All SHA-256 values have 256 bits, or 32 bytes. I've shortened each password for ease of viewing)
evansrb1:Robert Evans:F74EF..A1C19 mithcrj1:Robert Mitchell:AD523..CD2A4 alpha:John Colter:472CA..47289 radtke:Karen Radkte:DC8A4..013BB durbin:Lani Durbin:DC8A4..013BB→ It’s OK to set a high upper bound on password length, e.g. 128 or 256 characters, to prevent malcontents from burdening your server with pointlessly large chunks of password data. But limits such as “no more than 16 characters” are overly restrictive and should be avoided.
To verify a user’s password at login, we keep the user’s submitted password in memory – so it never needs to touch the disk – and compute its hash.
If the computed hash matches the stored hash, the user has fronted up with the right password, and we can let him login.
But Attempt Three still isn’t good enough, because Radtke and Durbin still have the same hash, leaking that they chose the same password.
Indeed, the text password will always come out as Dc8y4..0i3KK8, whenever anyone chooses it.
That means the crooks can pre-calculate a table of hashes for popular passwords – or even, given enough disk space, of all passwords up to a certain length – and thus crack any password already on their list with a single database lookup.
Attempt Four – salt and hash
We can adapt the hash that comes out for each password by mixing in some additional data known as a salt, so called because it “seasons” the hash output.
A salt is also known as a nonce, which is short for “number used once.”
Simply put, we generate a random string of bytes that we include in our hash calculation along with the actual password.
The easiest way is to put the salt in front of the password and hash the combined text string.
The salt is not an encryption key, so it can be stored in the password database along with the username – it serves merely to prevent two users with the same password getting the same hash.
For that to happen they would need the same password and the same salt, so if we use 16 bytes or more of salt, the chance of that happening is small enough to be ignored.
Our database now looks like this (the 16-byte salts and the hashes have been truncated to fit neatly):
evansrb1:Robert Evans:005A..D4A2:DCA34..45EF2 mithcrj1:Robert Mitchell::8337..93AC:B1E4F..CD6A4 alpha:John Colter:AB38F..3B87A:327A3..4ABE4 radtke:Karen Radkte:BB800..4AC2E:89812..AF23F durbin:Lani Durbin:F2F32..03829:A2311..17E52The hashes in this list, being the last field in each line, are calculated by creating a text string consisting of the salt followed by the password, and calculating its SHA-256 hash – so Radtke and Durbin now get completely different password data.
Make sure you choose random salts – never use a counter such as 000001, 000002, and so forth, and don’t use a low-quality random number generator like C’s random().
If you do, your salts may match those in other password databases you keep, and could in any case be predicted by an attacker.
By using sufficiently many bytes from a decent source of random numbers – if you can, use CryptoAPI on Windows or /dev/urandom on Unix-like systems – you as good as guarantee that each salt is unique, and thus that it really is a “number used once.”
Are we there yet?
Nearly, but not quite.
Although we have satisfied our three requirements (non-reversibility, no repeated hashes, and no hint of password length), the hash we have chosen – a single SHA-256 of salt+password – can be calculated very rapidly.
In fact, even hash-cracking servers that cost under $20,000 five years ago could already compute 100,000,000,000 or more SHA-256 hashes each second.
We need to slow things down a bit to stymie the crackers.
Attempt Five – hash stretchingThe nature of a cryptographic hash means that attackers can’t go backwards, but with a bit of luck – and some poor password choices – they can often achieve the same result simply by trying to go forwards over and over again.
Indeed, if the crooks manage to steal your password database and can work offline, there is no limit other than CPU power to how fast they can guess passwords and see how they hash.
By this, we mean that they can try combining every word in a dictionary (or every password from AA..AA to ZZ..ZZ) with every salt in your database, calculating the hashes and seeing if they get any hits.
And password dictionaries, or algorithms to generate passwords for cracking, tend to be organized so that the most commonly-chosen passwords come out as early as possible.
That means that users who have chosen un-inventively will tend to get cracked sooner.
→ Note that even at one million million password hash tests per second, a well-chosen password will stay out of reach pretty much indefinitely. There are more than one thousand million million million 12-character passwords based on the character set A-Za-z0-9.
It therefore makes sense to slow down offline attacks by running our password hashing algorithm as a loop that requires thousands of individual hash calculations.
That won’t make it so slow to check an individual user’s password during login that the user will complain, or even notice.
But it will reduce the rate at which a crook can carry out an offline attack, in direct proportion to the number of iterations you choose.
However, don’t try to invent your own algorithm for repeated hashing.
Choose one of these three well-known ones: PBKDF2, bcrypt or scrypt.
We’ll recommend PBKDF2 here because it is based on hashing primitives that satisfy many national and international standards.
We’ll recommend using it with the HMAC-SHA-256 hashing algorithm.
HMAC-SHA-256 is a special way of using the SHA-256 algorithm that isn’t just a straight hash, but allows the hash to be combined comprehensively with a key or salt:
- Take a random key or salt K, and flip some bits, giving K1.
- Compute the SHA-256 hash of K1 plus your data, giving H1.
- Flip a different set of bits in K, giving K2.
- Compute the SHA-256 hash of K2 plus H1, giving the final hash, H2.
In short, you hash a key plus your message, and then rehash a permuted version of the key plus the first hash.
In PBKDF2 with 10,000 iterations, for example, we feed the user’s password and our salt into HMAC-SHA-256 and make the first of the 10,000 loops.
Then we feed the password and the previously-computed HMAC hash back into HMAC-SHA-256 for the remaining 9999 times round the loop.
Every time round the loop, the latest output is XORed with the previous one to keep a running “hash accumulator”; when we are done, the accumulator becomes the final PBKDF2 hash.
Now we need to add the iteration count, the salt and the final PBKDF2 hash to our password database:
As the computing power available to attackers increases, you can increase the number of iterations you use – for example, by doubling the count every year.
When users with old-style hashes log in successfully, you simply regenerate and update their hashes using the new iteration count. (During successful login is the only time you can tell what a user’s password actually is.)
For users who haven’t logged in for some time, and whose old hashes you now considered insecure, you can disable the accounts and force the users through a password reset procedure if ever they do log on again.
The last wordIn summary, here is our minimum recommendation for safe storage of your users’ passwords:
- Use a strong random number generator to create a salt of 16 bytes or longer.
- Feed the salt and the password into the PBKDF2 algorithm.
- Use HMAC-SHA-256 as the core hash inside PBKDF2.
- Perform 40,000 iterations or more (August 2017).
- Take 32 bytes (256 bits) of output from PBKDF2 as the final password hash.
- Store the iteration count, the salt and the final hash in your password database.
- Increase your iteration count regularly to keep up with faster cracking tools.
Whatever you do, don’t try to knit your own password storage algorithm
So, what is better than storing a password correctly? Not storing it at all, but possibly validating the password against an LDAP server that is already storing passwords!
Session tracking
Okay, another issue that may be semi-related to passwords is session tracking. Your application may make features available to some users and not others. While you can do it based on their login (that's the easy part), the issue is an unscrupulous user might use their login and then craft a URL that might give access to tabs/panels they might not already have.
It turns out that the best way around this is to keep track of a session and login info on the server, then match any further requests against this data...if they match, great! if not, don't give the users any real results.
Not only do you want to make sure that any query from a user is from a valid session, but you also want to implement some type of session timeout. What this means is that your session ID expires after a certain period of non-use. This prevents a maliscious user from hijacking an "old" session and re-using an old session ID to bypass security. Modern STIG requirements have this set at a fairly short time, but if it gets too short it can bump someobdy off forcing them to re-enter data or re-initialize a session.
SSL
The final topic I wanted to hit on is using SSL certs. While you can make a http site, it is FAR more preferable to make your site https vice http. While not absolute protection, SSL does encrypt the traffic between the server and client. A common key is agreed upon and then is used to encrypt traffic between the two, so people can't "listen in" to your communications.
But to make this work, you need an SSL cert, and it turns out these aren't too expensive (at least for basic ones). We use one for the whole jhuep.com domain to provide https services for all of the servers.
Auditing/Audit Logs
This topic was suggested by a student, and while it is a very good topic, it is difficult to give detailed guidance.
To make auditing work, you need to have everything locked down. You need to enable auditing on the OS, and then compare those large and complex logs with that of your webservers or other applications (e.g. SQL).
Then, unless you have a somewhat expensive commercial tool that will correlate these logs, you need to have a very good background in the OS and the applications being audited to look for events indicating a breach of security...oh, and of course those logs should be kept on a different computer so that an attacker can't modify the logs to cover their tracks.
So yea, Auditing is very good, but isn't easy to do properly.
Security Certifications
So, these don't necessarily make anything safer, but often times, companies are looking to see if you do have some level of security background before they hire you.
I come from a government contractor background, and both Security+ and CISSP are the gold standards for security certifications when working for the govenment in one way or another. I know of several security certifications, but the primary candidates (found these good desciptions at Business News Daily) are:
 Certified Ethical Hacker (CEH): The Certified Ethical Hacker (CEH) is an intermediate-level credential offered by the International Council of E-Commerce Consultants (EC-Council). It's a must-have for IT professionals pursuing careers in ethical hacking. CEH credential holders possess skills and knowledge on hacking practices in areas such as footprinting and reconnaissance, scanning networks, enumeration, system hacking, Trojans, worms and viruses, sniffers, denial-of-service attacks, social engineering, session hijacking, hacking web servers, wireless networks and web applications, SQL injection, cryptography, penetration testing, evading IDS, firewalls, and honeypots.
Certified Ethical Hacker (CEH): The Certified Ethical Hacker (CEH) is an intermediate-level credential offered by the International Council of E-Commerce Consultants (EC-Council). It's a must-have for IT professionals pursuing careers in ethical hacking. CEH credential holders possess skills and knowledge on hacking practices in areas such as footprinting and reconnaissance, scanning networks, enumeration, system hacking, Trojans, worms and viruses, sniffers, denial-of-service attacks, social engineering, session hijacking, hacking web servers, wireless networks and web applications, SQL injection, cryptography, penetration testing, evading IDS, firewalls, and honeypots.
 CompTIA Security+: While Security+ is an entry-level certification, successful candidates should possess at least two years of experience working in network security and should consider first obtaining the Network+ certification. IT pros who obtain this certification possess expertise in areas such as threat management, cryptography, identity management, security systems, security risk identification and mitigation, network access control, and security infrastructure. The CompTIA Security+ credential is also approved by the U.S. Department of Defense to meet Directive 8140/8570.01-M requirements. In addition, the Security+ credential complies with the standards for ISO 17024.
CompTIA Security+: While Security+ is an entry-level certification, successful candidates should possess at least two years of experience working in network security and should consider first obtaining the Network+ certification. IT pros who obtain this certification possess expertise in areas such as threat management, cryptography, identity management, security systems, security risk identification and mitigation, network access control, and security infrastructure. The CompTIA Security+ credential is also approved by the U.S. Department of Defense to meet Directive 8140/8570.01-M requirements. In addition, the Security+ credential complies with the standards for ISO 17024.
So, when you here somebody ask "Are you 8570 compliant?" This is typically what they mean.
 Certified Information Systems Security Professional (CISSP): The Certified Information Systems Security Professional (CISSP) is an advanced-level certification for IT pros serious about careers in information security. Offered by the International Information Systems Security Certification Consortium, known as (ISC)2 (pronounced "ISC squared"), this vendor-neutral credential is recognized worldwide for its standards of excellence.
Certified Information Systems Security Professional (CISSP): The Certified Information Systems Security Professional (CISSP) is an advanced-level certification for IT pros serious about careers in information security. Offered by the International Information Systems Security Certification Consortium, known as (ISC)2 (pronounced "ISC squared"), this vendor-neutral credential is recognized worldwide for its standards of excellence.
CISSP credential holders are decision-makers who possess expert knowledge and technical skills necessary to develop, guide and then manage security standards, policies and procedures within their organizations. The CISSP continues to be highly sought after by IT professionals and is well recognized by IT organizations. It is a regular fixture on most-wanted and must-have security certification surveys.
CISSP is designed for experienced security professionals. A minimum of five years of experience in at least two of (ISC)2's eight Common Body of Knowledge (CBK) domains, or four years of experience in at least two of (ISC)2's CBK domains and a college degree or an approved credential, is required for this certification. The CBK domains are Security and Risk Management, Asset Security, Security Architecture and Engineering, Communications and Network Security, Identity and Access Management (IAM), Security Assessment and Testing, Security Operations, and Software Development Security.
Keeping up with events
Okay, last thing, even with all this, if you are in software, it behooves you to keep up with current events. I've found that finding a good podcast that you can listen to while commuting is a very good way to keep up with things that are happening in the world of security.
 There are many good ones, but my current favorite is Security Now, which can be found at https://twit.tv/shows/security-now. This is a weekly 2 hour podcast that has great coverage of topics AND it counts for maintaining CPEs that are necessary for any of those Security Certifications that I listed above!
There are many good ones, but my current favorite is Security Now, which can be found at https://twit.tv/shows/security-now. This is a weekly 2 hour podcast that has great coverage of topics AND it counts for maintaining CPEs that are necessary for any of those Security Certifications that I listed above!