
JDBC
(Java and Databases)
Required Reading
The Java Tutorial on JDBC Database Access: Introduction
Read the Tutorial on JDBC basics after you read this Chapter. It covers setting up your database connection with Netbeans and Java, which I will cover in the notes as well. In Java, the Derby database is part of the JDK, so you don't even need to install MySQL, or any other database. Unfortunately, in the documentation, There are now three sample databases that ship with the install, a "sample", "travel", and "vir" database which you can use to explore JDBC with.
What is a JDBC?
JDBC is a standard interface that allows you to easily connect to a database and send SQL commands to the database. The returned data can be read and manipulated within Java programs. Remember, JDBC is not SQL! It allows you to access any database using the same JDBC commands, so it abstracts out certain idosyncrasies of each database.
JDBC consists of two parts
- The JDBC API, which is your Java classes that allow you to make calls to the connected database
- The JDBC Driver Manager, which is the "under the hood" interface that allows the JDBC APIs to convert your calls to the vendor specific calls to the database.
The JDBC API allows you to perform several database connections and functions, regardless of which database is actually being used.
- Establish database connection
- Initiate queries
- Create stored queries
- Access structure of query result
It turns out there are several versions of JDBC, the latest being version 4.3.
Year |
JDBC version |
JDK Implementation |
| 2017 | JDBC 4.3 | Java 9 |
| 2014 | JDBC 4.2 | Java 8 |
| 2011 | JDBC 4.1 | Java 7 |
| 2007 | JDBC 4.0 | JDK 1.6 (Java SE 6) |
| 2001 | JDBC 3.0 | JDK 1.4 |
| 1999 | JDBC 2.1 | JDK 1.2 |
| 1997 | JDBC 1.2 | JDK 1.1 |
Each version has made some improvements onto the basic JDBC API. The Main new features introduced were
- JDBC 4.3
- current stable version which was released in September 2017
- support of sharding
- extra support for the connection builder interface
- this version will contain the interface of the sharding key and the sharding builder
- JDBC 4.2
- The main feature of the 4.2 version is it will support the ref cursor.s
- JDBC 4.1
- Automatic loading of java.sql.Driver for type 4 drivers
- Added try-with-resource
- enhanced date type value of timestamp
- support the java object additional mappings to the JDBC types
- JDBC 4.0
- Automatic loading of java.sql.Driver for type 4 drivers
- ROWID data type support
- National Character Set Conversion Support (NCLOB)
- SQL/XML and XML Support. (SQLXML)
- Better CLOB and BLOB support
- DataSet and annotations
- JDBC 3.0
- Supports SQL99 standard
- Enhanced Metadata APIs
- Named parameters in Callable Statements
- Added DATALINK and BOOLEAN types
- Holdable cursors in the ResultSet
- Multiple open ResultSets
- Savepoints in Transactions
- JDBC 2.0
- Maps SQL3 data types
- ARRAY
- BLOB
- CLOB
- Scrollable ResultSets
- Batch Updates
- Maps SQL3 data types
JDBC consists of two basic parts. The first is the JDBC API, winch is a purely Java-based API allowing a programmer to make JDBC calls to a database. The second part is a JDBC Driver Manager which communicates with vendor specific drivers that perform the real communications. Each vendor supplies a JDBC driver which connects to the JDBC Driver Manager, allowing JDBC to talk to that particular database implementation.
It turns out there are several types of JDBC drivers.
- JDBC Type 1:JDBC-ODBC Bridge plus ODBC Driver.
- This provides JDBC access via Microsoft ODBC drivers. Sun provides a JDBC-ODBC Bridge driver, which is appropriate for experimental use and for situations in which no other driver is available.
- JDBC Type 2: A native code driver.
- This type of driver converts JDBC calls into native DB API calls on the client API for Oracle, Sybase, Informix, DB2, or other DBMS.
- JDBC Type 3: Pure Java Driver
- This style of driver translates JDBC calls into the DB independent network protocol, which is then translated to a DBMS protocol by a middleware server. The middleware provides connectivity to many different databases.
- JDBC Type 4: Direct-to-Database Pure Java Driver.
- This style of driver converts JDBC calls into the vendor specific protocol used directly by DBMSs, allowing a direct call from the client machine to the DBMS server and providing a practical solution for intranet access.
Typically, vendors now provide Type 4 drivers with their databases. These provide the best compatibility and performance of all of the driver types.
I found an interesting article on www.developer.com, which talked about the shortcomings of the Type 4 drivers.
Among developers who are knowledgeable about the behind-the-scenes workings of middleware data connectivity using JDBC drivers, the limitations of a Type 4 driver are generally undisputable. These include:
- The need to write and maintain code specific to each supported data source. Even with modern framework-based object-relational mapping (ORM) models, JDBC Type 4 drivers typically require the use of proprietary code to support variant database features such as BLOBs and CLOBs, high availability, and XA.
- Poor and/or inconsistent driver response times or data throughput performance when the driver is deployed in certain runtime environments (such as different JVMs) or with ORMs and application servers.
- The inability to tune or optimize critical applications, or the ability to do so only with considerable application downtime.
- Poor virtual machine (VM) consolidation ratios due to inefficient runtime CPU usage and high memory footprints.
- Deployment headaches such as having to deploy multiple JARs to support different JVMs or database versions, or DLLs to support certain driver or database functionality
So, even though Type 4 drivers are good, there are some concerns that they should be better.
Data Types
Since SQL is a different language than Java, it follows that it has different data types. Therefore, when you try to interface with SQL, there is a mapping of Java to SQL data types. JDBC also handles the unpleasant reality that Databases may use different storage primitives. For example, Microsoft SQL has boolean object types, but MySQL doesn't! Since the JDBC drivers convert your Java types to a type compatible with the connected database, you don't have to worry about these differences.
As of JDBC 4, the following is a mapping of the Java to SQL data types.
Java Data Type |
JDBC Data Type |
SQL Data Type |
| boolean | BIT | SMALLINT |
| short | SMALLINT | SMALLINT |
| byte | TINYINT | SMALLINT |
| int, java.lang.Integer | INTEGER | INTEGER |
| long, java.lang.Long | BIGINT | BIGINT |
| float, java.lang.Float | REAL | REAL |
| double, java.lang.Double | DOUBLE | DOUBLE |
| java.math.BigDecimal | NUMERIC, DECIMAL | DECIMAL(p, s) |
| java.lang.String | CHAR | CHAR(n) |
| java.lang.String | VARCHAR, LONGVARCHAR | VARCHAR(n) |
| java.lang.String | CLOB | CLOB(n) |
| byte[] | BINARY | CHAR(n) FOR BIT DATA |
| byte[] | VARBINARY, LONGVARBINARY | VARCHAR(n) FOR BIT DATA |
| byte[] | VARBINARY, LONGVARBINARY | BLOB(n) |
| byte[] | ROWID | |
| java.sql.Blob | BLOB | BLOB(n) |
| java.sql.Clob | CLOB | CLOB(n) |
| java.sql.Date | DATE | DATE |
| java.sql.Time | TIME |
TIME |
| java.sql.Timestamp | TIMESTAMP | TIMESTAMP |
| java.io.ByteArrayInputStream | None | BLOB(n) |
| java.io.StringReader | None | CLOB(n) |
| java.io.ByteArrayInputStream | None | CLOB(n) |
| java.net.URL | DATALINK | DATALINK |
| java.sql.SQLXML | None | XML |
First a few words on Database Design
One of the things you should do when dealing with persistant storage (Database or other) is try to keep the implementation localized. This means you should set up the data access in one location, so that if you change your implementation later on, you don't have to track through your whole codebase looking for changes.
In addition, design your data access so that you have methods returning Java Objects instead of JDBC types. This way if you change from JDBC to Hibernate at a later date, you only have to change the code that directly talks to the data store.
Lastly, set up your code so that all you need to do is implement the SQL calls that a database "expert" gives you. Odds are, the person creating the queries won't be a Java (or C# for that matter) programmer, but a DBA of some type. If you set up your code to easily swap out the SQL calls with new versions as needed, you'll make life easier in the end.
Connecting to the Database
Step 1: Create a SimpleJDBC project
Step 2: Right click on Simple JDBC and select Properties. Then select the Java Build Path
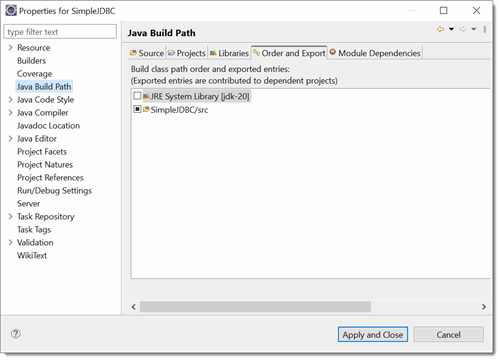
So to get JDBC to work, you need to provide the drivers that the database vendor supplies to make the JDBC connection. First make a lib directory under the SimpleJDBC project then find the driver file (for Windows, it is shown below...note it's location)
Now we need to get the connector, once again go to the MySQL download page and download the jdbc connector. You can grab the platform independent version that will work on Windows.
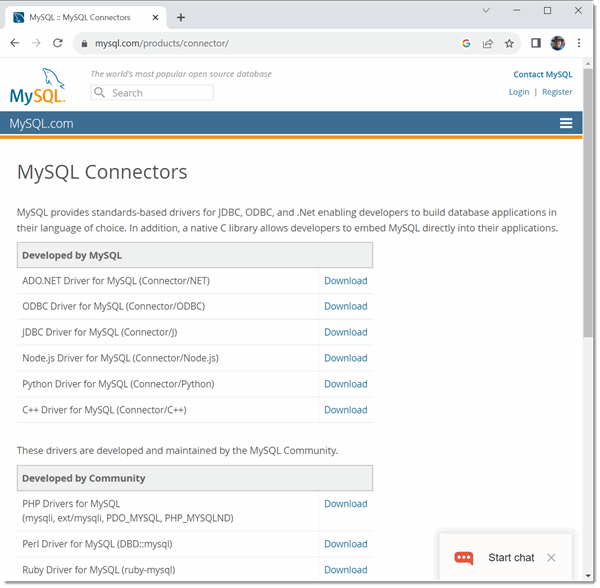
Now place a copy of the jar file in you lib directory for your project
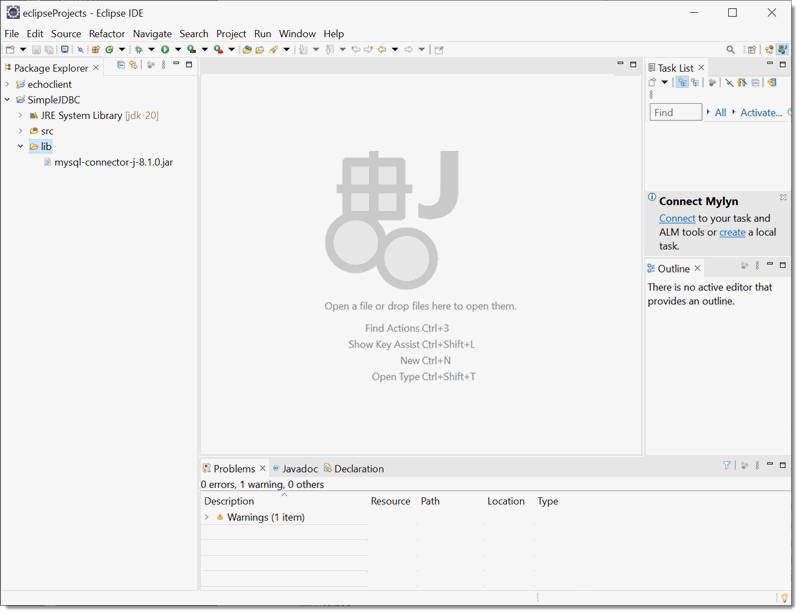
Now right click on the SimpleJDBC project and click on Properties and Java Build Path. Add the JAR you just added to the build path.
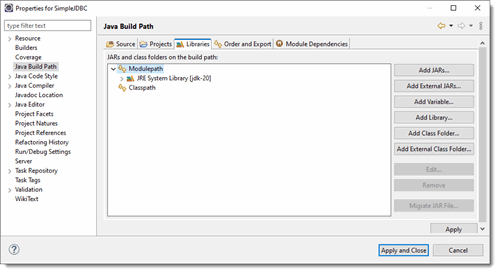
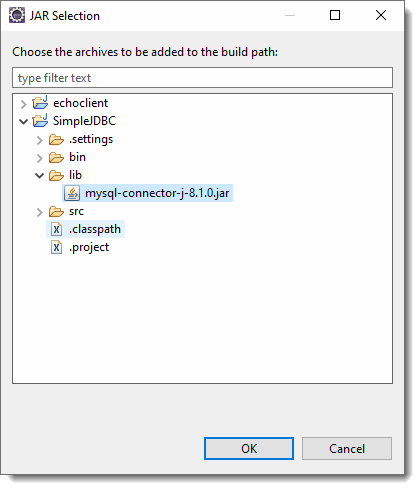
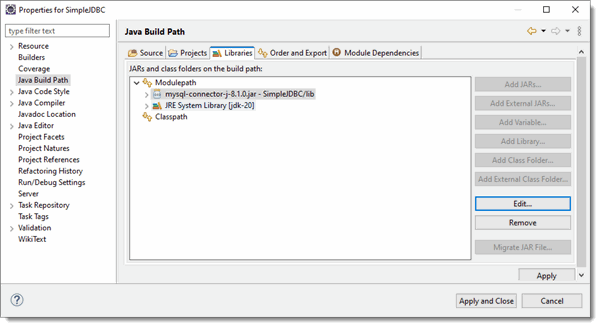
Click Apply and Close
Before we continue on, we need to talk about some key classes that are used with JDBC
Connection objects
A Connection object's database is designed to provide you with more than just Statement objects. The Connection object also lets you look up information (MetaData and Version) about the database you've connected too.
Statement objects
Now that we have a connection, we'd like to be able to query the database from our Java program. One of the simplest, but not necessarily the most efficient, is to make a Statement object. You need a Statement object to run SQL queries.
There are three kinds of Statements
- Statement: Execute simple SQL queries without parameters
- Prepared Statement: Execute pre-compiled SQL queries with or without parameters
- Callable Statement: Execute a call to a database stored procedure.
The first type we'll look at is a simple Statement. To create a Statement object, you use the Connection object from earlier and call createStatement(). If you look at the Statement interface, you'll note that there are no actual classes that are listed that implement the interface...so where does it come from? It is provided by the sql drivers you have loaded for the specific database.
When you
Once you have the Statement object, it allows you to query the database with one of:
- execute(): Several ways to execute a statement, with possible multiple ResultSets. You get the ResultSets no return values expected other than success
- executeQuery(): Executes the given SQL statement, which returns a single ResultSet object.
- executeUpdate(): Executes the given SQL statement, which may an INSERT, UPDATE, or DELETE statement or a SQL statement that returns nothing, such as any other SQL DDL statement. The method returns an int which is the number of rows affected by the SQL command.
- executeBatch(): Submits a batch of commands to the database for execution.
When we call executeQuery(), it returns a ResultSet object, which is a table of database information. The String you pass to the executeQuery() method is a regular SQL query string.
If we use the MyFirstDatabase database we created in the SQL chapter, we can get the People table by calling
statement.executeQuery("select * from People");
Batch commands:
Rather than submit a single SQL command at a time, JDBC allows you to build up a set of commands in a single batch and submit them as a single set. This only makes sense when using DDL statements such as drop, create or insert as you are not looking for ResultSet's from these commands. The Statement object has an addBatch() command which adds the given SQL command to the current list of commands for this Statement object. The commands in this list can be executed as a batch by calling the method executeBatch.
The Statement.executeBatch() command returns an int[] array.
The Java API tells us this about executeBatch():
This command submits a batch of commands to the database for execution and if all commands execute successfully, returns an array of update counts. The int elements of the array that is returned are ordered to correspond to the commands in the batch, which are ordered according to the order in which they were added to the batch. The elements in the array returned by the method executeBatch may be one of the following:
- A number greater than or equal to zero -- indicates that the command was processed successfully and is an update count giving the number of rows in the database that were affected by the command's execution
- A value of SUCCESS_NO_INFO -- indicates that the command was processed successfully but that the number of rows affected is unknown. If one of the commands in a batch update fails to execute properly, this method throws a BatchUpdateException, and a JDBC driver may or may not continue to process the remaining commands in the batch. However, the driver's behavior must be consistent with a particular DBMS, either always continuing to process commands or never continuing to process commands. If the driver continues processing after a failure, the array returned by the method BatchUpdateException.getUpdateCounts will contain as many elements as there are commands in the batch, and at least one of the elements will be the following:
- A value of EXECUTE_FAILED -- indicates that the command failed to execute successfully and occurs only if a driver continues to process commands after a command fails
Great, we have a ResultSet, so how do we use it?
ResultSet
A ResultSet contains the results of a SQL query. It is represented by a table with rows and columns. A ResultSet object maintains a cursor pointing to its current row of data. Initially the cursor is positioned before the first row. The next() method moves the cursor to the next row, and because it returns false when there are no more rows in the ResultSet object, it can be used in a while loop to iterate through the result set.
A default ResultSet object is not updatable and has a cursor that moves forward only. Thus, you can iterate through it only once and only from the first row to the last row. It is possible to produce ResultSet objects that are scrollable and/or updatable.
ResultSets have grown since the first JDBC version. Originally, you could only scroll forward in them. In JDBC 2, you could then scroll forward and backward. In JDBC 3, you could actually use a ResultSet to update the database it came from using the concurrency option, and you can keep ResultSets open even after you made another statement or closed a database connection.
Typically, you will make a ResultSet that allows scrolling, such as:
connection.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_READ_ONLY);
This will provide you with a ResultSet that you can scroll around in, but is read-only and will not be used to update the source table. For more options on ResultSet, see the API Documentation on ResultSet.
Some common ResultSet methods to move about in the database and their usage is shown below:
ResultSet method |
Use |
| next() | moves the cursor forward one row. Returns true if the cursor is now positioned on a row and false if the cursor is positioned after the last row. |
| previous() | moves the cursor backwards one row. Returns true if the cursor is now positioned on a row and false if the cursor is positioned before the first row. |
| first() | moves the cursor to the first row in the ResultSet object. Returns true if the cursor is now positioned on the first row and false if the ResultSet object does not contain any rows. |
| last() | moves the cursor to the last row in the ResultSet object. Returns true if the cursor is now positioned on the last row and false if the ResultSet object does not contain any rows. |
| beforeFirst() | positions the cursor at the start of the ResultSet object, before the first row. If the ResultSet object does not contain any rows, this method has no effect. |
| afterLast() | positions the cursor at the end of the ResultSet object, after the last row. If the ResultSet object does not contain any rows, this method has no effect. |
| relative(int rows) | moves the cursor relative to its current position. |
| absolute(int row) | positions the cursor on the row-th row of the ResultSet object. |
| getMetaData() | Returns a ResultSetMetaData object containing information about the columns in the ResultSet (e.g. column names, data types, etc...) |
| close() | Releases the JDBC and database resources. Unless holdability is set, the ResultSet is automatically closed when the associated Statement object executes a new query |
In addition to moving around the cursor (line to line), you can get data from the database by first positioning the cursor at a row of data (see the above methods), and then calling one of the getXXX methods to get the data from one of the columns in the row that the cursor points to. Each method takes either an absolute column index, or a String corresponding to the column's label. It returns the data type shown in the table.
Oh, and just to keep you confused, unlike almost all other programming languages, SQL arrays start with index 1 not 0, so the first column in a ResultSet is column 1 not column 0.
Java Data type |
ResultSet method |
| Array | getArray() |
| Ascii Stream | getAsciiStream() |
| BigDecimal | getBigDecimal() |
| Binary Stream | getBinaryStream() |
| Blob | getBlob() |
| boolean | getBoolean() |
| byte | getByte() |
| bytes[] | getBytes() |
| Clob | getClob() |
| Date | getDate() |
| double | getDouble() |
| float | getFloat() |
| int | getInt() |
| long | getLong() |
| SQLXML | getSQLXML() |
| String | getDate() |
| Time | getTime() |
| Timestamp | getTimestamp() |
| URL | getURL() |
Okay, at this point we have a database Connection, a Statement, and a ResultSet. Let's pull some data from the database!
Simple JDBC
Okay, now we are going to create a test class. This won't be too fancy, just listing the models in the cameras table. Now I've made an additional user, called "test" that can do some simple calls to the database, without any admin privileges.
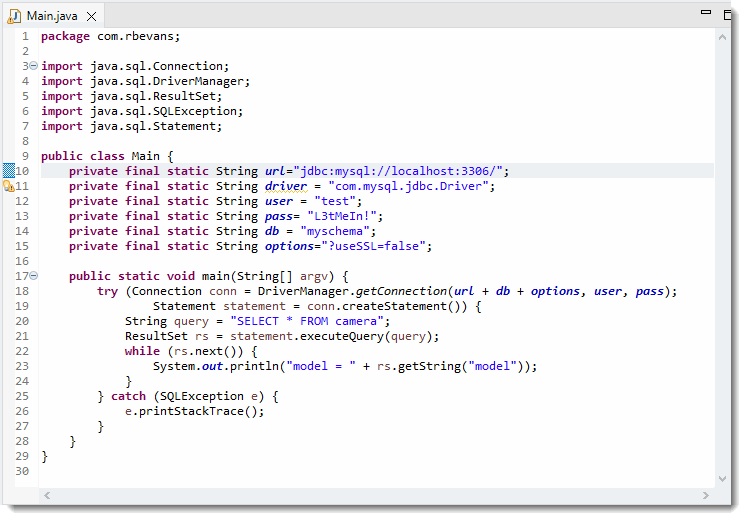
Let's walk through this example before we run it.
The first few lines are just setting up String constants that are used in the connection.
- private final static String url="jdbc:mysql://localhost:3306/";
This is the connection type, host and port you are connecting to. If you connected to a different SQL server, you would swap out "mysql" for the name of the type of SQL server you would be using. "localhost" is used for your *local* host, if you want to connect to web7.jhuep.com, you need to change localhost to web7.jhuep.com. Lastly the port number is depdendent on the server your are using. MySQL uses port 3306.
- private final static String driver = "com.mysql.jdbc.Driver";
This is the full qualified class name for the Driver you use. The above is what is used for MySQL.
- private final static String user = "test";
The user you want to connect as. For your internal testing, you can make a new account on the database (make sure and give it permissions to access the schema) or use your root account.
- private final static String pass = "L3tMeIn!";
The password used for the account you want to connect to. Now some of you may be saying "wait, you are putting a *password* in your program?" Yes, there is no way around it, but remember, the classes that would contain this on the server aren't publically available, and the accounts should only have the access needed to support the web apps that use them.
- private final static String db="myschema";
The name of the schema you want to connect to
- private final static String options="?useSSL=false";
Okay, modern MySQL drivers want to use SSL connections, which we aren't setting up for this class. You need to explicitly tell the connection to not use SSL with "modern" drivers. Note that you won't include this option on connections to web7 (I'm using an older version of MySQL on that system).
Okay, now that we have that taken care of, how about the code in the main() method...
The first bit of code is called a "try-with-resources" block. It is a classic try-catch design, but the idea here is that at the start of the try block, you define several reources. The try statement then ensures that each resource is *closed* at the end of the statement. Any object that implements the java.lang.Closeable interface may be placed in the header of the block. (see https://docs.oracle.com/javase/tutorial/essential/exceptions/tryResourceClose.html for a more detailed explanation).
So, we first open a connection to our database. The connection consists of a URL+ dbName + options string, plus a username and password. Now you might be tempted to say "well why not make a single connection and then use it everywhere in my program for as long as I want to instead of making a new connection for every call?" An excellent idea, only databases are set up that way. The connections on the server end timeout, and it is almost impossible to manage them that way, so this design is the best way to ensure functioning connections.
try (Connection conn = DriverManager.getConnection(url + db + options, user, pass);
Statement statement = conn.createStatement()) {
The next line creates a JDBC Statement object that is used to handle the SQL calls. Now for this *trivial* example I use a Statement object, and there are some times you can get away with one, but...Statements are dangeours, particularly with String inputs. These are the source of those "SQL Injection" attacks that you may have heard of. Under most circumstances you would use a PreparedStatement object to create your SQL statment, which prevents SQL Injection exploits.
We can now make our SQL statement. This is just SQL that works on your Database Server. It is *not* JDBC, but rather the same SQL calls you would make directly to your server.
String query = "SELECT * FROM camera";
After that we pass the sql to the Statement object, and execute the query. Note that sometimes you use executeQuery() to just get information, and sometimes you use executeUpdate() to make changes to your database.
ResultSet rs = statement.executeQuery(query);
Note the resulsts of the query are sent to a ResultSet object. The ResultSet contains the response to the query you sent to the server. Data is accessed from the ResultSet by iterating through the set (iterating through the returned rows of information), and then pulling off the data you want.
while (rs.next()) {
System.out.println("model = " + rs.getString("model"));
}
This just iterates through each row of the ResultSet and pulls off the "model" column for each row. Now you can acces columns by their "name" or their "number". Numbers begin with 1 *NOT* 0 for JDBC rows (go figure). From a maintenance perspective, it is always more stable and reliable to use the name of the column (rarely changes) vs. the position in the row.
Lastly, we close the ResultSet to free up the resources. Note that we don't have to explicitly close the Statement or Connection, since we have them defined in the try.
Note:
- While the driver name is "com.mysql.jdbc.Driver", this is now deprecated. It should still work, but the correct name is "com.mysql.cj.jdbc.Driver".
- options should now include "?useSSL=false&serverTimezone=US/Eastern"
If we run the example:
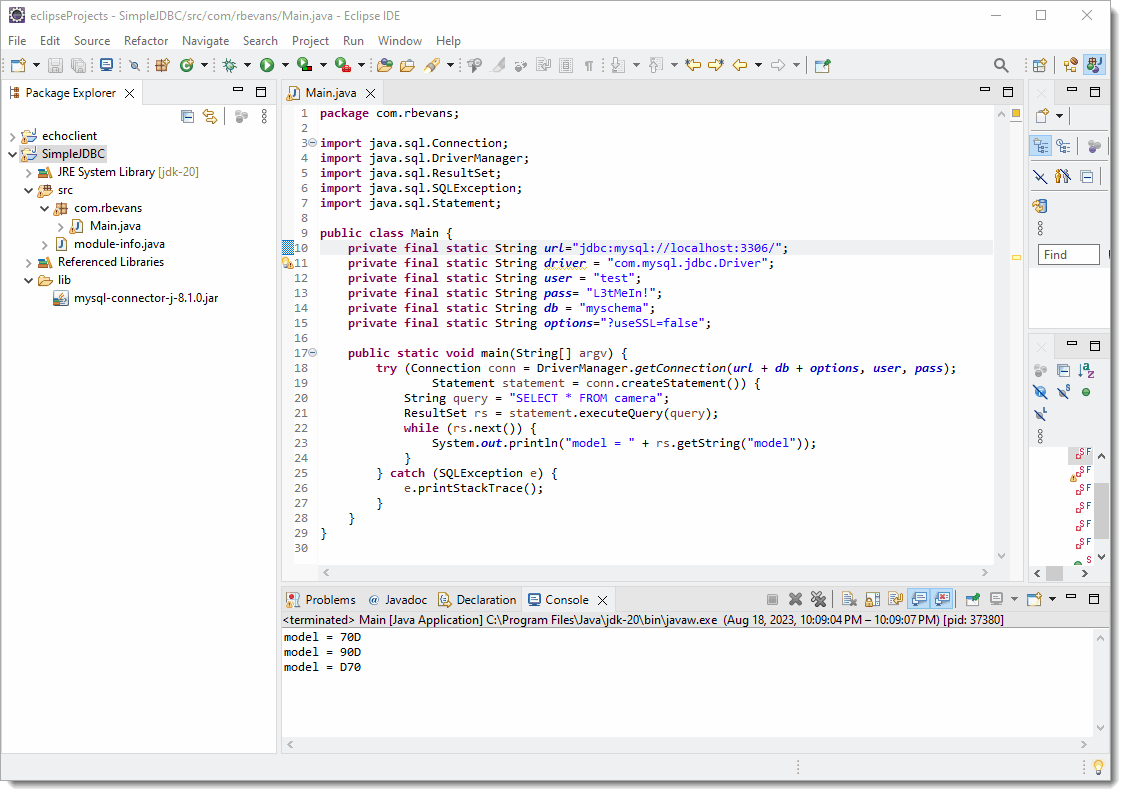
You can see the results.
ResultSetMetaData
When you get a ResultSet, you can use the getMetaData() method to get a ResultSetMetaData object. This object can be used to get information about the number of, types and properties of the columns in a ResultSet. A few common methods are:
ResultSetMetaData method |
purpose |
| getColumnCount() | Returns the number of column in the ResultSet |
| getColumnLabel(int column) | Returns the column's suggested title |
| getColumnType(int column) | Retrieves the designated column's SQL type |
Updatable ResultSets
If, when you make your Statement object, you specify a non read-only concurrency, you can use the ResultSet to update the original table. You need to position the cursor using the methods we've already discussed, but you can use the
resultSet.updateXXX(int column Num, value)
resultSet.updateXXX(String columnName, value)
methods to update a value in the ResultSet, then call
resultset.updateRow()
to update the database.
If you want to insert new rows into ResultSet
- Move the cursor to insert a row
resultset.moveToInsertRow();
- Set specific values in insert row
resultSet.updateXXX(column, value);
- Move insert row to result set and database
resultSet.insertRow();
- Return cursor to last location in resultset
resultSet.moveToCurrentRow()
If you want to delete a record, position the cursor and then delete the row in the ResultSet
resultSet.deleteRow();
JDBC Example
In the SimpleJDBC example above, we queried an already created database. The next question is, how would you build one on the fly?
Remember when I talked about Statements earlier, there were several types, and two of them were:
- executeUpdate(): Executes the given SQL statement, which may an INSERT, UPDATE, or DELETE statement or a SQL statement that returns nothing, such as any other SQL DDL statement. The method returns an int which is the number of rows affected by the SQL command.
- executeBatch(): Submits a batch of commands to the database for execution.
You can use executeUpdate() to call individual SQL commands to drop or build tables, or you can bundle all other commands into a single batch request and do it with executeBatch(). Why should you batch commands? Typically, whenever you send over one command at a time, it takes longer than if you bundle them as a set. Of course, if you do a single command at a time, you can respond to error conditions easier.
Download and open the Eclipse project StandaloneJDBC. The Main class of the project is almost identical to the SimpleJDBC example. The biggest difference is the inclusion of the Database class, which manages not only the connection to the database, but it rebuilds the database for each new connection. This doesn't make sense for any production system, but for learning or debugging, it ensures you start with the same data each time.
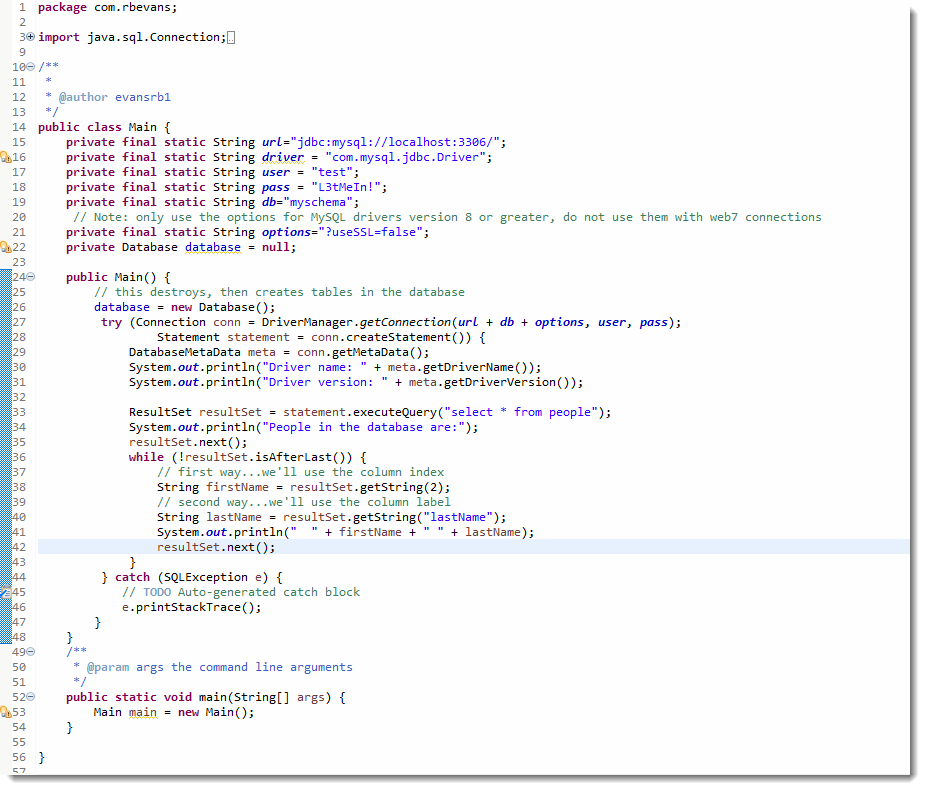
And here is the Database.java file which rebuilds the database
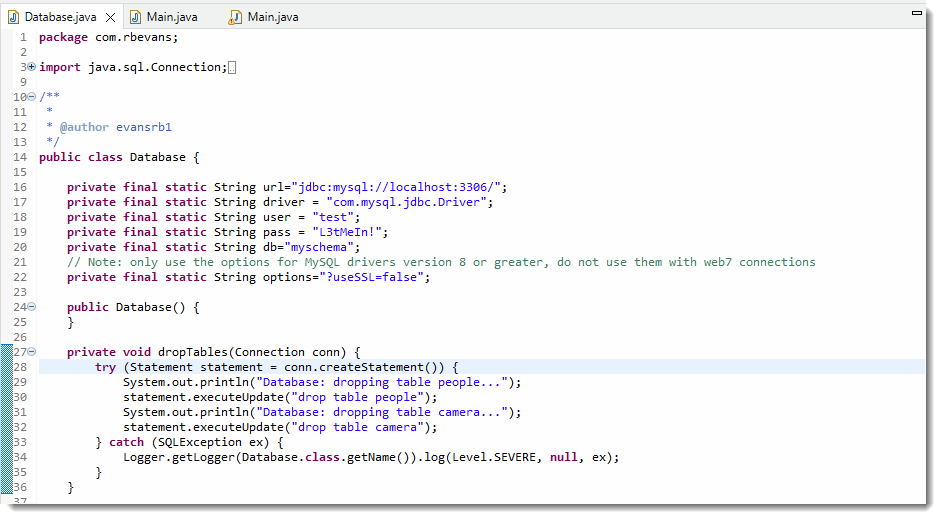
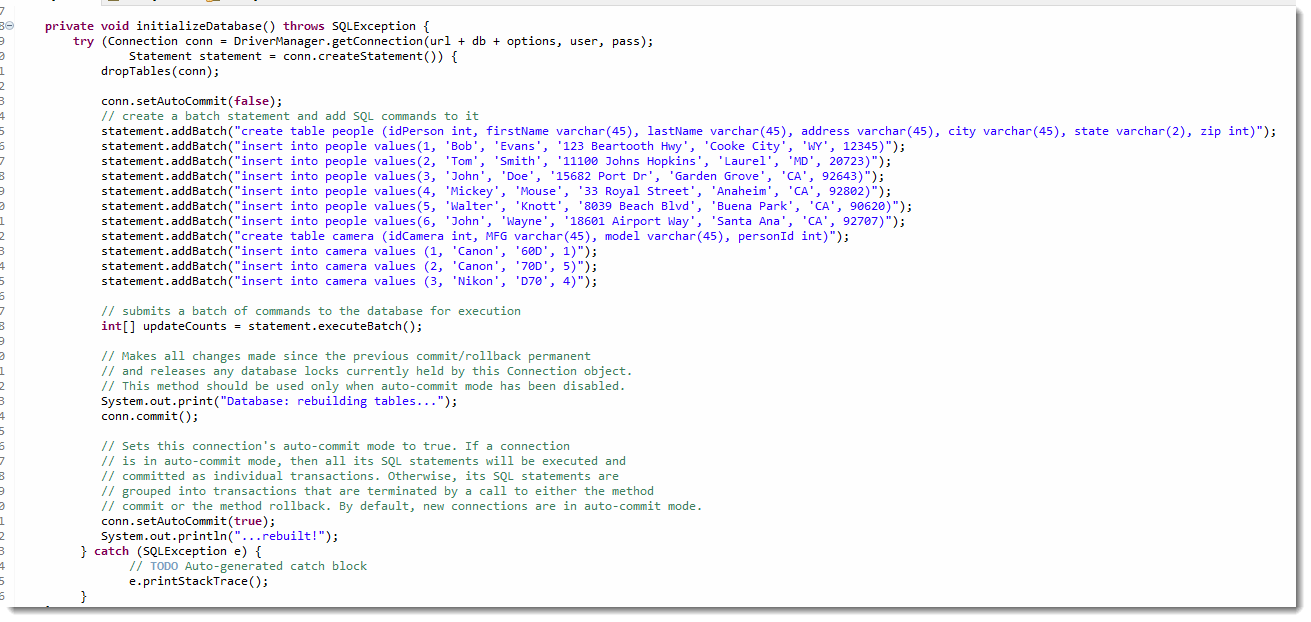
If you take a look at the Database class, you'll see two interesting methods. The first id dropTables(), which drops both tables using the executeUpdate() command. The first time you run this application, you probably won't get any errors, because it will drop the tables you built earlier. If you delete one of the tables, you'll see the error message when you try to drop a nonexistent table.
The other method is the intializeDatabase() method. In this method we first turn autoCommit off for our connections, which lets us add several SQL commands to a batch query. We manually commit() the batch and then turn autoCommit back on.
Prepared Statements
If you are going to repeatedly use the same type of SQL statement with only minor modifications, you can use a PreparedStatement. PreparedStatements are parameterized statements that a "pre-compiled" in the database. Each time you use the statement, you simply replace some of the marked parameters using the setXXX methods on the PreparedStatement.
It turns out that using prepared statements also prevents attacks on a SQL server based on SQL Injection. The vulnerability is present when user input is either incorrectly filtered for string literal escape characters embedded in SQL statements or user input is not strongly typed and thereby unexpectedly executed.
For our homework, you should use PreparedStatements. It is true, that if user input is not incorporated into a query, then a Simple Statement can be safely used as a mangled query can't be added to it. But, for our homeworks, use PreparedStatements.
For example, let's say you had a SQL statement that looked like this:
UPDATE employees SET salary = 10000 WHERE id = 101;
Now, you need to loop through set of id numbers and set the salaries for each one. Instead of making new SQL statements for each one you can make a PreparedStatement instead
PreparedStatement Statement = connecction.prepareStatement("UPDATE employees SET salary = ? WHERE id = ?";
This lets you use the statement repeatedly by setting the "?" fields in the PreparedStatement...
int[] newSalaries = getSalaries();
int[] employeeIDs = getIDs();
for (int i=0; i < employeeIDs.length; i++) {
pStatement.setInt(1, newSalaries[i]);
pStatement.setInt(2, employeeIds[i]);
pStatement.executeUpdate();
}
There are setXXX method for all major data types. It turns out that Query data obtained from a user through an HTM form may have SQL or special characters that mary require escape sequences to properly pass to the database. To handle these special characters, pass the String from the form to the PreparedStatement.setString() method which will automatically escape the string as necessary.
If you want to clear all of the set parameters values int the statement, you can call the clearParameters() method as well.
SQL Exceptions and Warnings
Almost every JDBC method can throw a SQLException in response to any type of error that the SQL statement may generate. If more than one error is generated, they are chained together.
SQLExceptions contain:
- The description of the error (use getMessage())
- The SQL State (Open Group SQL specification) identifying the exception (use getSQLState())
- A SQL vendor-specific integer error code (use getErrorCode())
- A chan to the next SQLException (use getNextException())
One of the primary rules of dealing with SQL exceptions is to not make assumptions about the state of a transaction after an exception occurs. The safest bet is to attempt to rollback to return to the initial state.
SQLWarnings are rare, but they may provide information about the database access warnings. These warnings are chained to the object whose method produced the warning.
Connections, Statements, and ResultSets can receive warning messages. You call getWarning() to obtain a warning object and getNextWarning() for any chained warnings (similar to the SQL Exceptions).
Warnings are cleared on the object each time the statement is executed.
Transactions
By default, after each SQL statement is executed the changes are automatically committed to the database. I've already shown you, in the StandaloneJDBC example, that you can turn off auto-commit to group two or more statements together into a transaction. The basic sequence is:
connection.setAutoCommit(false);
<bundle the statements>
connection.commit();
connection.setAutoCommit(true);
What I didn't include in that example was the ability to rollback the changes that had succeeded if one of them eventually failed. If you call
connection.rollback();
In the catch clause for a SQLException, it drops all changes since the previous call to commit(). It also releases any database locks held by that Connection object. The commit() method forces all changes since the last call to commit to become permanent.
An example code snippet of this sequence is as follows:
connection.setAutoCommit(false);
try {
statement.executeUpdate(...);
statement.executeUpdate(...);
connection.commit();
} catch (SQLException sqle) {
try {
connection.rollback();
} catch (SQLException sqle) {
System.err.println("oops: rollback didn't work!);
}
}
Web Application Issues
Okay, this issue can come up with web applications...we saw it pop up after it had been dormant for a while.
If your app works on your local machine, but then it fails on the server, particularly if you get a driver not found error, you need to manually load the driver in the main class constructor.
public class Data extends HttpServlet {
public final static String DRIVER="com.mysql.cj.jdbc.Driver";
public Data() {
super();
try {
Class.forName(DRIVER);
} catch (ClassNotFoundException cnfe) {
cnfe.printStackTracke();
}
}
This should load the driver before you make your getConnection() call.